Key capabilities
Chat UI
Browser-based streaming chat on port 3000. Works with any loaded model.
OpenAI-compatible API
Drop-in
/v1 endpoints on port 8000. Works with LangChain, Open WebUI, and any OpenAI client.Model downloads
50+ models from the built-in catalog. Paste any Hugging Face repo ID.
Fine-tuning
LoRA, QLoRA, and full fine-tune from the browser. No notebooks.
Quantization
Compress any model to AWQ or NVFP4 on your own GPU, then serve it or push it to Hugging Face.
Multi-node clustering
Automatic peer discovery. One model sharded across all GPUs in the cluster.
Federated serving
One endpoint, many models — the master routes each request to the node that holds the model.
Model stacking
Run several models per node. They persist across restarts and replay on boot.
Prometheus metrics
/metrics endpoint for Grafana, Prometheus, VictoriaMetrics.Verified hardware
GB10 Grace Blackwell systems (unified memory, cluster-native)
| Hardware | Manufacturer | GPU memory | Price | Status |
|---|---|---|---|---|
| DGX Spark | NVIDIA | 128 GB unified | $3,999 | ✅ Verified — TP=4, 487 GB cluster |
| Ascent GX10 | ASUS | 128 GB unified | $2,999 | ✅ Verified |
| Pro Max with GB10 (FCM1253) | Dell | 128 GB unified | TBD | ✅ Supported |
| ZGX Nano AI Station | HP | 128 GB unified | TBD | ✅ Supported |
Data center / AI accelerators
| GPU | VRAM | Architecture | Tier |
|---|---|---|---|
| B200 | 192 GB HBM3e | Blackwell | Data center |
| H200 | 141 GB HBM3e | Hopper | Data center |
| H100 SXM5 / PCIe | 80 GB HBM3 | Hopper | Data center |
| A100 80 GB | 80 GB HBM2e | Ampere | Data center |
| A100 40 GB | 40 GB HBM2e | Ampere | Data center |
| L40S | 48 GB GDDR6 ECC | Ada Lovelace | Inference / viz |
| L40 | 48 GB GDDR6 ECC | Ada Lovelace | Inference / viz |
| A40 | 48 GB GDDR6 ECC | Ampere | Data center / viz |
| L4 | 24 GB GDDR6 ECC | Ada Lovelace | Edge inference (72W) |
| A30 | 24 GB HBM2 | Ampere | Data center |
| A10 | 24 GB GDDR6 ECC | Ampere | Inference |
| A16 | 4× 16 GB GDDR6 | Ampere | VDI |
| A2 | 16 GB GDDR6 | Ampere | Edge |
Professional workstation
| GPU | VRAM | Architecture | Tier |
|---|---|---|---|
| RTX PRO 6000 Blackwell | 96 GB GDDR7 ECC | Blackwell | Pro workstation |
| RTX 6000 Ada | 48 GB GDDR6 ECC | Ada Lovelace | Pro workstation |
| RTX 5000 Ada | 32 GB GDDR6 ECC | Ada Lovelace | Pro workstation |
| RTX 4500 Ada | 24 GB GDDR6 ECC | Ada Lovelace | Pro workstation |
| RTX 4000 Ada | 20 GB GDDR6 ECC | Ada Lovelace | Pro workstation |
| RTX A6000 | 48 GB GDDR6 ECC | Ampere | Pro workstation |
| RTX A5000 | 24 GB GDDR6 ECC | Ampere | Pro workstation |
| RTX A4000 | 16 GB GDDR6 ECC | Ampere | Pro workstation |
| RTX A2000 12 GB | 12 GB GDDR6 ECC | Ampere | Pro entry |
Consumer — GeForce RTX 50 series (Blackwell, 2025)
| GPU | VRAM | MSRP |
|---|---|---|
| RTX 5090 | 32 GB GDDR7 | $1,999 |
| RTX 5080 | 16 GB GDDR7 | $999 |
| RTX 5070 Ti | 16 GB GDDR7 | $749 |
| RTX 5070 | 12 GB GDDR7 | $549 |
| RTX 5060 Ti | 8 / 16 GB GDDR7 | ~499 |
Consumer — GeForce RTX 40 series (Ada Lovelace, 2022–2024)
| GPU | VRAM | MSRP |
|---|---|---|
| RTX 4090 | 24 GB GDDR6X | $1,599 |
| RTX 4080 Super | 16 GB GDDR6X | $999 |
| RTX 4070 Ti Super | 16 GB GDDR6X | $799 |
| RTX 4070 Super / 4070 | 12 GB GDDR6X | $599 |
| RTX 4060 Ti 16 GB | 16 GB GDDR6 | $499 |
| RTX 4060 Ti / 4060 | 8 GB GDDR6 | 399 |
Consumer — GeForce RTX 30 series (Ampere, 2020–2022)
| GPU | VRAM |
|---|---|
| RTX 3090 Ti / 3090 | 24 GB GDDR6X |
| RTX 3080 Ti | 12 GB GDDR6X |
| RTX 3080 12 GB | 12 GB GDDR6X |
| RTX 3070 Ti / 3070 | 8 GB |
| RTX 3060 | 12 GB GDDR6 |
| RTX 3060 Ti | 8 GB GDDR6 |
Live cluster demo
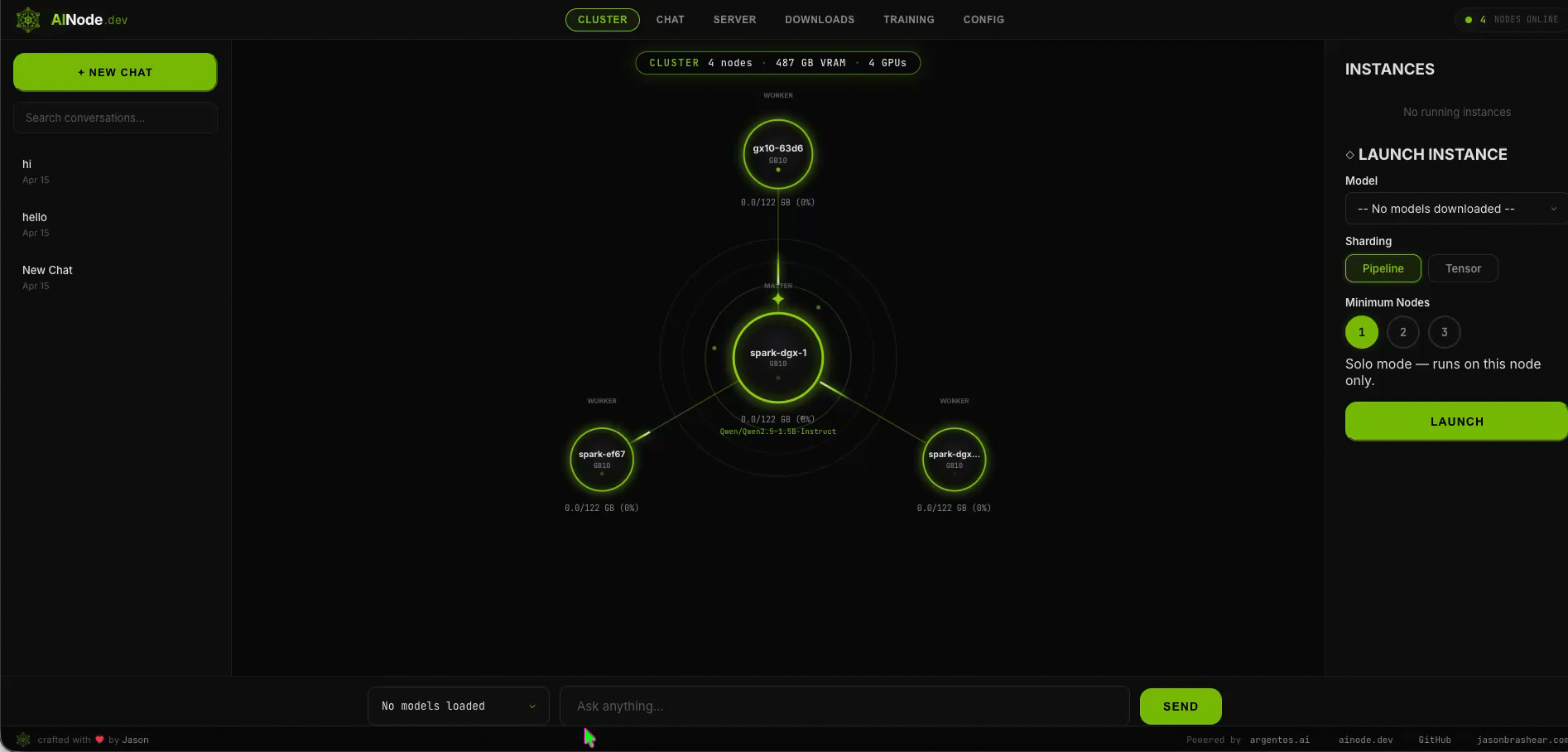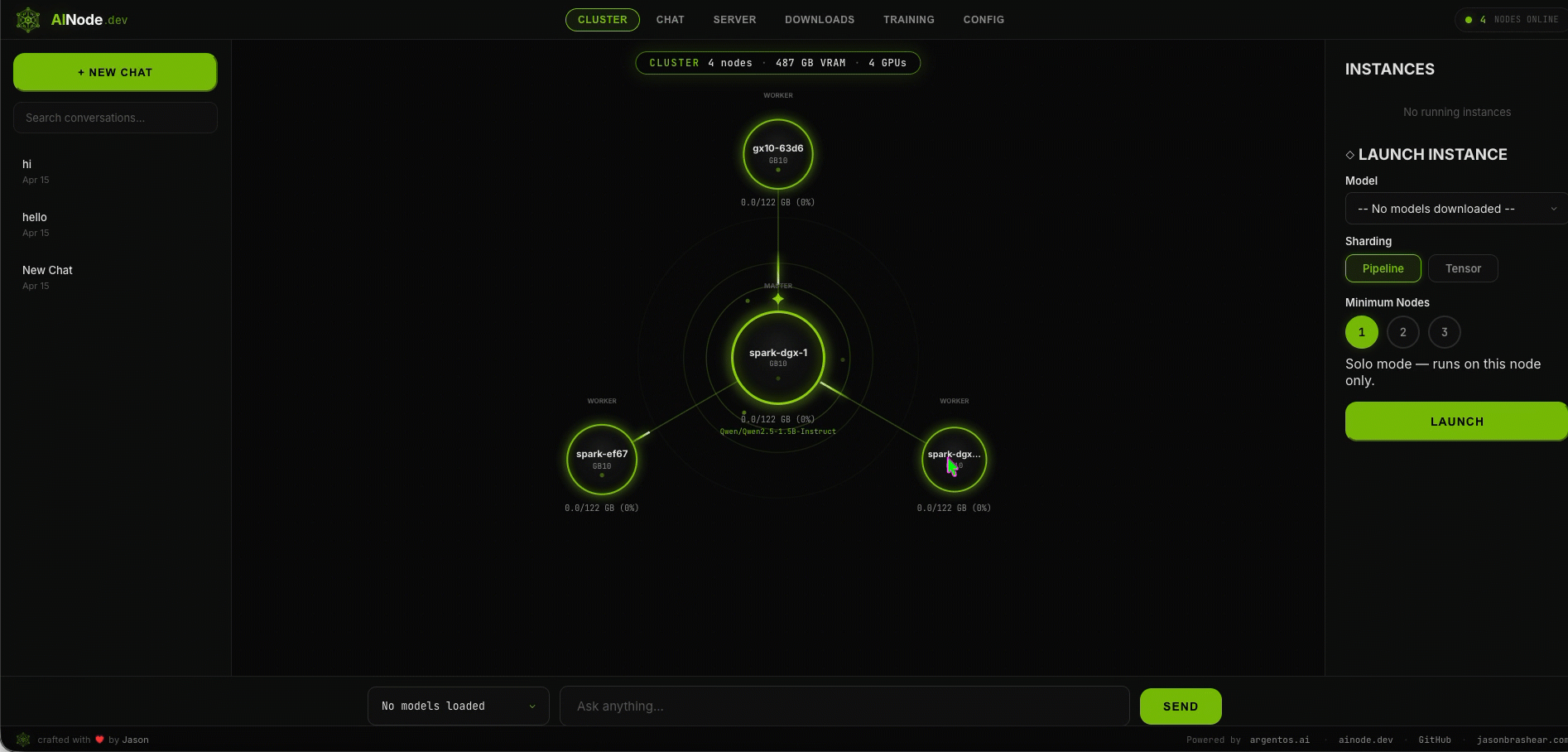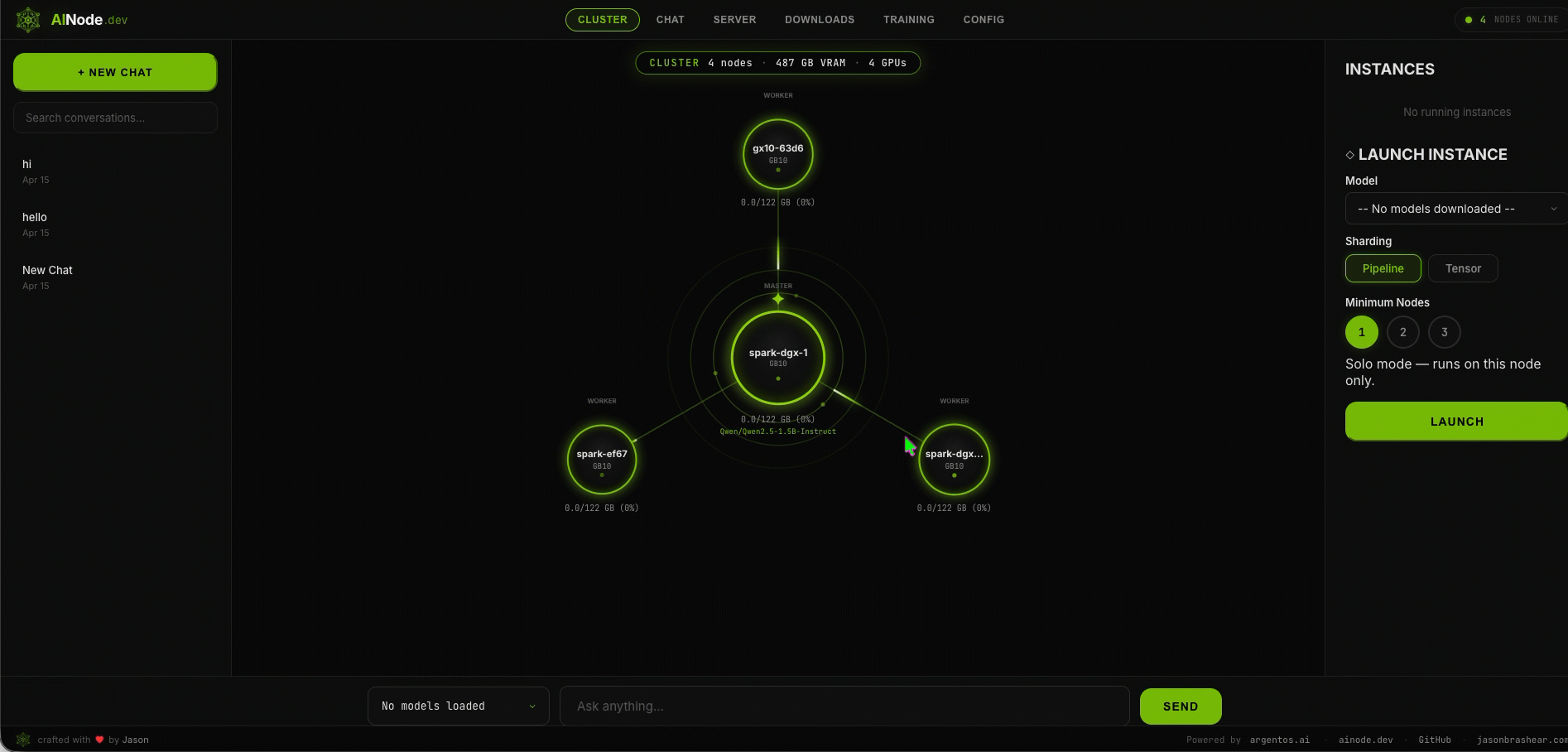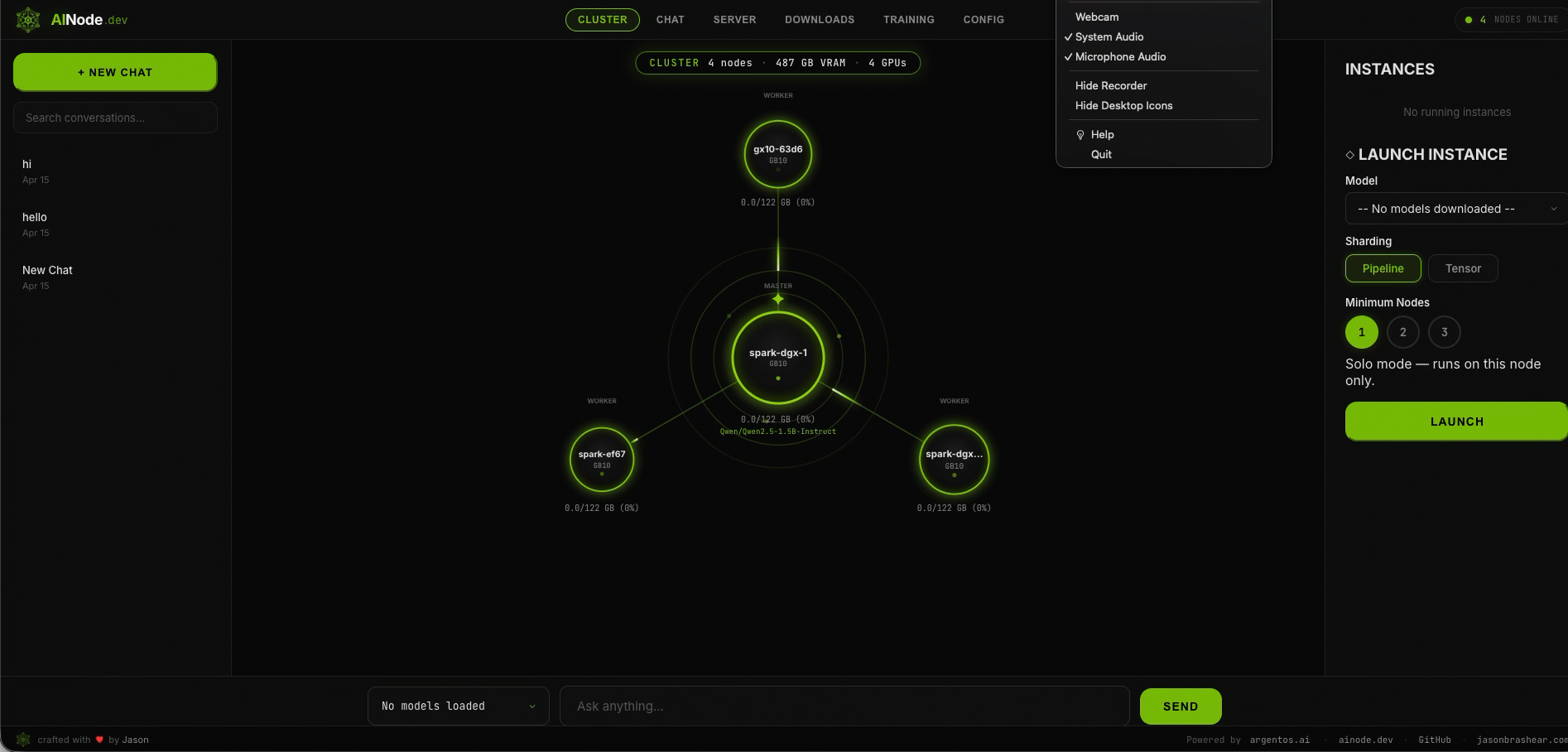
Architecture
AINode ships as a single unified container image. Every node in the cluster runs the same image.ainode update.